Mitt förra inlägg om metadata gav en del kommentarer som ”Varför använder du inte själv Dublin Core?”.
Det verkar vara en viss övertygelse om att man inte kan predika om bra saker utan att själv använda det. Jag tillämpar många av mina tips som jag ger, men inte alla. Det kan bero på att de inte passar mig eller för att jag inte har tid eller resurser att implementera dem. Dessutom faller det inte alltid in med min målsättning, vilket är en grundförutsättning för att ens tänka på dem.
I fallet med Dublin Core så har jag för närvarande ingen vinning att använda det och väljer däför att lägga min tid på annat. En prioritering helt enkelt. Därmed inte sagt att den prioriteringen är särskilt smart eller bra, men det är mitt val och du behöver inte göra detsamma. Dublin Core kanske passar just dig perfekt? (För övrigt genereras Dublin Core automatiskt tillsammans med mina inlägg, så jag behöver inte ens lyfta ett finger, men det är inte det som är min poäng.)
För att försöka reda ut begreppen ger jag tre klockrena exempel där metadata används och ger maskinsökbara gränssnitt:
Dating – Match.se
En förutsättning för datingsajter av olika slag är sökfunktionen. Där brukar man kunna söka efter kön, ålder, längd, intressen och geografisk placering.
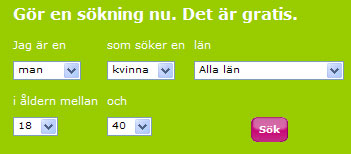
Alla dessa sökegenskaper är metadata om personen man söker. Ju fler metadata man söker efter, desto mer begränsat blir sökresultatet (och därmed troligare den person man söker).
En förutsättning för att detta ska fungera är att alla personer anger fullständig metadata om sig själv. Det är ofta här problemet ligger, inte minst inom dating, utan också med allt webbinnehåll. Det finns för lite information om webbinnehållet för att kunna utföra mer än fritextsökningar.
En sökmotor som Google skulle aldrig klara att söka på detta viset. Den är inte optimerad för denna typ av metadata.
Musik – iTunes
Det gäller vilken musikspelare som helst egentligen, men med iTunes kan du ”tagga” låtarna med exempelvis årtal, genré, antal spelningar och betyg. Genom detta kan man få fram låtlistor med enbart 90-tal, enbart pop, mest spelade eller högst betygsatta.
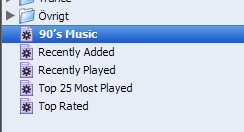
Den metadatastandard som används för detta kallas ID3.
Med andra ord hjälper metadata dig att komma åt ditt material på olika sätt – genom att leta upp en låt i en bestämd genré eller söka efter ”den där låten” som José González spelar på akustisk gitarr. Söka efter kvinnor i 25-årsåldern i hela Sverige eller skumma igen en lista med alla kvinnor som bor i Stockholms län är heller inget problem.
Metadata är en grundläggande term inom informationsarkitektur, och något som är nödvändigt för att få en bred, flerkanalig automatisk väg till informationen.
Den semantiska webben
Tro det eller ej, men den semantiska webben är baserad på metadata. Tanken med semantik (som handlar om ords betydelser) är att märka upp en webbsida med huvudrubrik, underrubrik, viktiga ord och så vidare. Genom att visa en lista över dessa viktiga har vi samtidigt metadata.
Alltså fungerar semantik också som metadata. Men metadata behöver nödvändigtvis inte vara semantik.