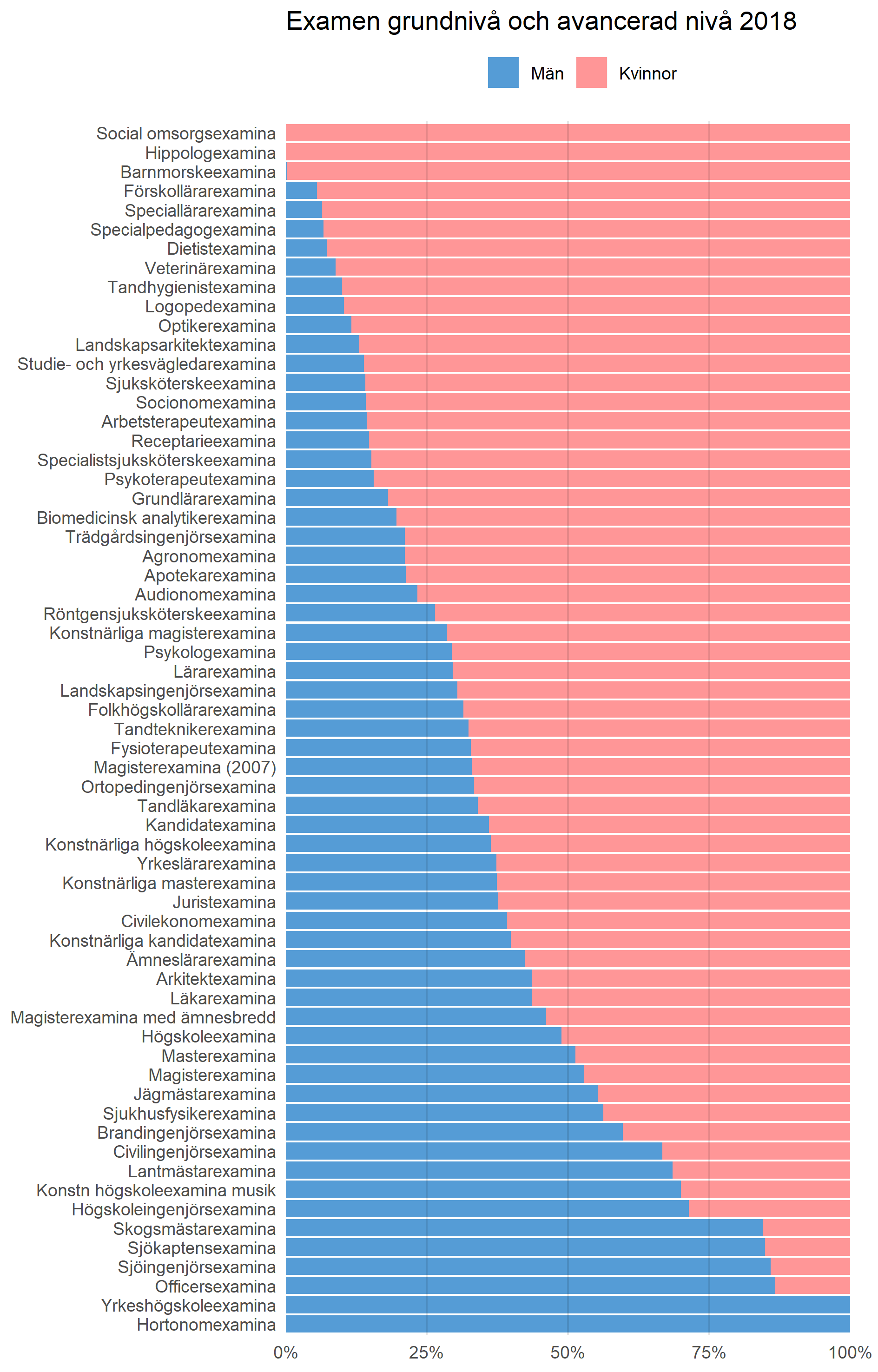
SVT Rapport har under flera månader låtit sin Y-axel växa så att dödstalen ser mindre och mindre ut. Medan TV4 säger sig ha gjort ett misstag, kommer SVT fortsätta som tidigare.
Under ett par år har jag hållit en föreläsning om hur man kan luras med statistik. I föreläsningen pratar jag bland annat om hur olika axlar på diagram kan ändra vår uppfattning av det budskap som kommuniceras.
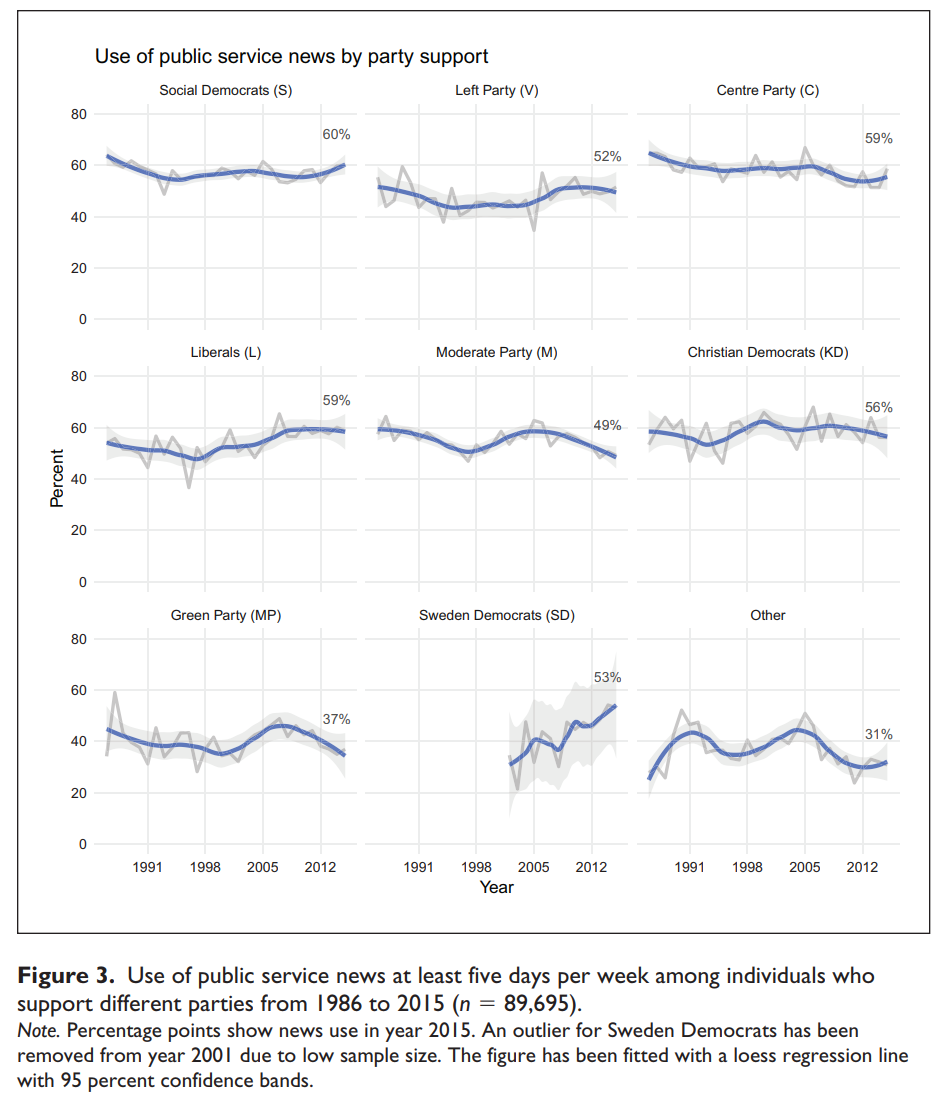
Titta exempelvis på bilden nedan, som visar samma data i alla diagram, men där värdet på Y-axeln förändras. I diagrammet till höger ser det ut som att kurvan inte pekar lika mycket uppåt som de andra två diagrammen.
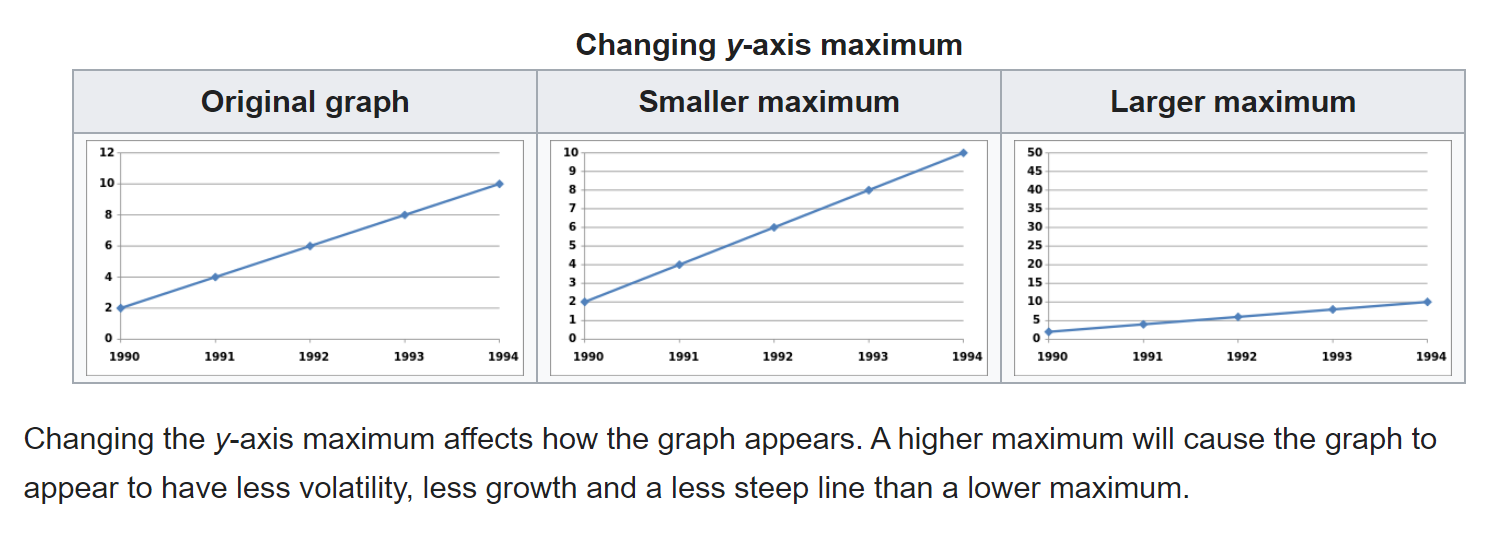
Ställer man dessa diagram sida vid sida är det uppenbart att de ger olika intryck. Däremot kan det vara svårt att upptäcka den här typen av grafer när man inte har något att jämföra med. Eller när diagrammen förändras över tid.
På Twitter hade några uppmärksammat att SVT Rapport sakta ökade Y-axeln över tid, så att kurvan över antalet döda med covid-19 ser plattare och plattare ut. För att bekräfta detta passade jag på att göra ett liknande diagram med dödstalen för covid-19. Dessvärre är det bara tre bildrutor från några slumpmässigt utvalda sändningar.
För att få lite mer substans än bara tre bildrutor passade jag därför på att i stället försöka plocka ut alla diagram och sätta ihop dem till ett videoklipp som du kan se nedan.
Diagram med dödstal
I videoklippet nedan ser du alla diagram som SVT Rapport visat om dödstalen covid-19 från 29 maj 2020 till 11 februari 2021. Notera särskilt hur Y-axeln (den vertikala axeln) förändras från 120, 200, 250, 300 och slutligen till 400.
Varför ökar Y-axeln på detta vis?
Flera personer har kontaktat SVT och frågat varför Y-axeln förändrats som den gör.
En representant för SVT menade att det är flera som gör nyhetsgrafiken och att det mycket väl skulle kunna vara tvärtom vissa dagar (det vill säga, att Y-axeln minskar), och att det beror på vilka exempel man väljer att plocka ut. Av videon ovan att döma verkar så inte vara fallet.
Andra som frågat SVT har fått svaret att SVT helt enkelt kopierat Folkhälsomyndighetens grafer (och formaterat dem efter sin egen grafiska profil), men att Folkhälsomyndighetens grafer även visar det faktiska antalet dödsfall per dag som är högre (och inte som i videon ovan från SVT, som har ett glidande medelvärde). SVT säger att:
Vi vill inte göra egna grafer då det mycket lätt blir fel. Att fylla i varje enskild dags stapel i ljust grått är ett mycket stort jobb och tillför ganska lite då det är utvecklingen vi vill visa på.
Vi kommer därför fortsätta som nu [och] får bemöta kritiken med sakliga argument.
Man kan hålla med SVT om vikten av att minska risken för att det blir fel, liksom att undvika merjobb. Men i andra vågskålen har vi Sveriges största nyhetsprogram som hellre presenterar missvisande diagram än lägger tid på att anpassa dem för det innehåll de ska kommunicera. De säger heller inte att det är ett medelvärde de presenterar.
Men nu finns det även en tredje förklaring! Folkhälsomyndigheten har ställt sig frågande inför SVT:s uppgifter och när SVT dubbelkollar visar det sig att det faktiskt är SVT:s egna diagram, men att det är datajournalisterna som tagit fram den för webben (och Rapport sedermera bara plockat bort de överflödiga uppgifterna från diagrammet). SVT vill dock inte ändra detta diagram på grund av resursskäl:
Att vi inte bett våra datajournalister om en egen graf till Rapport beror på hur vi prioriterar våra resurser. Våra datajournalister arbetar med mängder av olika projekt och prioriterar de arbetsuppgifter som är viktigast och mest intressanta journalistiskt. Att producera en egen graf till Rapport är helt enkelt inte prioriterat även om det vore välkommet.
Ett förslag till SVT: i stället för att göra diagram över smittspridningen i USA:s delstater och andra länders smittspridning till webben, lägg lite av de resurserna på att göra ett (1) diagram av Sverige som är mindre missvisande, som sedan kan visas i SVT Rapport.
TV4 visade ett snarlikt diagram om utvecklingen av konstaterade fall med covid-19 där Y-skalan också hade förstorats. De meddelade att det var ett misstag som inte ska upprepas.
Metod
Diagrammen identifierades med hjälp av ett neuralt nätverk tränat av Johan Strömbom, som kontaktade mig på Twitter och delade koden med mig. Han tränade modellen på några dagsaktuella inslag av SVT Rapport. Därefter körde jag programmet på alla SVT Rapports sändningar under pandemin från och med mars 2020. Programmet gick igenom alla sändningar, bildruta för bildruta, för att identifiera om det fanns ett diagram. När programmet stötte på ett diagram spottade det ut stillbilderna, och dessa bilder lät jag sedan strömma genom FFmpeg för att skapa videoklippet.
Fördelen med den här metoden är att den är helt automatiserad och har förmågan att själv plocka ut alla diagram. SVT Rapport (och SVT mer generellt) har i hög grad standardiserad grafik som ser i mångt och mycket likadan ut år efter år, vilket gör det till en relativt enkel uppgift (men notera ändå de subtila skillnaderna i diagrammen över tid, vilket indikerar att de inte helt och hållet återanvänds från en tid till en annan!). Sannolikheten att denna klassificerare missar några diagram är därför väldigt låg, även om sannolikheten aldrig är noll (klassificeraren kunde exempelvis inte identifiera diagram med perspektivförskjutning som dök upp häromdagen).
Läs mer
- Därför är Rapports graf över dödstal så missvisande: ”Vi vill inte göra egna grafer” (Emanuel Karlsten, 22 februari 2021)
Uppdaterat 5 mars: Det här inlägget uppdaterades med nya uppgifter om att det faktiskt var SVT som gjorde grafen, inte Folkhälsomyndigheten som SVT påstod.