Efter det amerikanska presidentvalet blev frågan om filterbubblor och ekokammare aktuell som en av förklaringarna till Donald Trumps framgång. I denna text ska jag ge några skäl till varför effekten av filterbubblor och ekokammare är överdriven, delvis baserat på min egen forskning.
Ett vanligt förekommande fenomen är att människor framför allt tar del av nyheter och information som bekräftar vad de redan tror. Detta brukar förklaras med selektiv exponering och confirmation bias. Åtminstone i forskningen. I massmedier är detta ofta beskrivet som filterbubblor och ekokammare.
Men journalister och massmedier är dock duktiga på att lyfta fram just filterbubblor och ekokammare och ge dem ovanligt stor förklaringskraft, kanske för att det går trender och att många journalister använder sociala medier själva (dock långt ifrån alla) där exempel efter exempel på falska nyheter, propaganda och uppenbara lögner har spridits.
Det går naturligtvis inte sticka under stolen med att filterbubblor och ekokammare kan vara en bidragande orsak. Men det intressanta är ju i vilken utsträckning det är en bidragande orsak, och i nuläget finns det inte mycket som tyder på att den är speciellt stor.
För att sammanfatta forskningen i en mening kan jag säga att föreställningen om filterbubblors och ekokammares inverkan är tämligen överdriven. Det finns flera skäl till att vara skeptisk till det och jag ska redogöra för ett godtyckligt antal av skälen i denna text.
Men först:
Vad är filterbubblor och ekokammare?
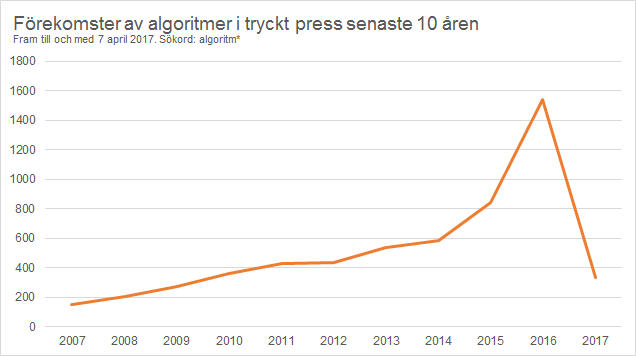
Med filterbubblor menas oftast algoritmer som styr vad som ska visas i exempelvis en sökmotors resultatsidor och i våra nyhetsflöden på sociala medier. Dessa resultatsidor och nyhetsflöden påverkas i sin tur av vårt användande av dem.
Då människor generellt föredrar information som bekräftar vad de redan tror (ett väletablerat faktum i forskningen), är idén att människor klickar sig allt djupare in i en omslutande ”bubbla” av information som allt mer bekräftar vad de redan tror. På så vis återkommer (”ekar”) välbekant information dag ut och dag in.
Forskningen om filterbubblor är dock inte speciellt omfattande, utan startade i mångt och mycket med Eli Parisers bok The Filter Bubble. Det är förvisso ingen akademisk bok, utan i mångt och mycket en bok om Eli Parisers egna erfarenheter och farhågor av att använda Google med några illustrativa exempel.
Boken har gett upphov till mycket diskussion och forskningsfrågor, men det är kanske bäst att se boken på just det viset och inte som ett bevis på problemen med sökmotorer eller sociala medier.
1. Alla algoritmer är inte personaliseringar
Först av allt verkar det finnas en vanlig missuppfattning att algoritmer kan likställas med personalisering. Men algoritmer är långt ifrån synonymt med personalisering.
En algoritm är helt enkelt instruktioner som en dator följer för att slutföra en specifik uppgift, precis som vi människor följer ett recept i en kokbok. En algoritm kan därför vara väldigt enkel (exempelvis ”Om A är lika med 1, så ska B utföras”) eller betydligt mer komplex, och kan slutföra vilken typ av uppgift som helst (det vill säga, den behöver inte vara relaterad till personalisering). Det är samma för recept, du kan göra ett bakverk eller ett sprängmedel.
Personalisering innebär, i detta sammanhang, att sociala medier och sökmotorer kommer ihåg och anpassar sig efter vad just du gillar, klickar på eller liknande. Klickar du exempelvis på länkar om att mänsklig klimatpåverkan är falsk så kommer mer länkar om att mänsklig klimatpåverkan är falsk att visas framöver. Risken är då uppenbar: Du får tills slut bara se länkar om hur mänsklig klimatpåverkan är falsk.
Men då missar man alla andra algoritmer som också finns i sociala medier och sökmotorer. Google arbetar med att kontrollera sanningshalten i påståenden, att öka mångfalden på YouTube genom att infoga relaterade videor, med mera. Facebook har också algoritmer som visar relaterade länkar till en upplagd länk, vilket har visat sig minska effekten av ekokammare. Kort sagt, det finns många algoritmer och några kan öka filterbubblan, andra minska den. Vi vet alltså inte ens åt vilket håll pendeln lutar, generellt sett.
Men detta är den tekniska biten. Forskningen visar också att människor tröttnar på att höra samma sak flera gånger, även under kortare tidsperioder som ett par timmar, och letar sig därför vidare till annan information som säger emot deras övertygelser. Med andra ord, tekniken kanske har ändrats drastiskt på senare år, men människor är fortfarande stenåldersmänniskor.
Så vad är konsekvenserna av filterbubblor på sikt? Det är svårt att säga, men vad som däremot är säkert att säga att det är lätt att överdriva och antingen prata om en av två ytterligheter där tekniken styr människorna eller där människorna styr tekniken. Sanningen pendlar dock fram och tillbaka mellan dessa två ytterligheter beroende på sammanhang.
Därför är varningarna om filterbubblor och ekokammare också överdrivna eftersom det verkar bygga på antagandet att människor bara vill bekräfta sina övertygelser och att algoritmer bara syftar till att personalisera innehållet i sociala medier, vilket endast är sant om man ignorerar alla andra tillfällen då de inte gör det.
2. Preferenser är inte val
Även om det är ett etablerat faktum att människor föredrar nyheter och information som bekräftar vad de redan tror, följer det inte att de också exponerar sig för sådana nyheter. Inte heller följer det att de undviker nyheter som säger emot deras övertygelser. Det går alltså alldeles utmärkt att föredra nyheter som bekräftar ens övertygelser, och ändå exponeras för nyheter som går emot ens övertygelser. Det är också ett väletablerat forskningsresultat.
Det är nämligen viktigt att skilja mellan vad man själv föredrar, vad man själv väljer och vad man exponeras för som andra har valt. Det vi väljer kan också skapa en preferens för det vi har valt (så kallad mere exposure effect), vilket innebär att det inte är så enkelt att människor har en färdig åsikt och sedan inhämtar information som bekräftar den. De kan mycket väl vara tvärtom: de har inte en åsikt, utan blir exponerade för en specifik information som sedan hjälper till att forma en åsikt.
Vi får en mängd nyheter som dyker upp i våra flöden som inte bekräftar vad vi redan tror, och vår benägenhet att klicka vidare till dessa nyheter påverkas av sociala faktorer (som hur populära de är, vem som är avsändare, vilka relaterade nyheter det finns, vilket humör man är på, med mera), och inte bara huruvida innehållet bekräftar vad vi redan tror.
3. Våra vänner är inte homogena
I sociala medier sägs det ofta att vi blir vänner med människor som tycker likadant som oss själva. Forskningen visar att det stämmer i viss utsträckning. Men forskningen visar också att vi är relativt dåliga på att bedöma vilken politisk övertygelse våra vänner har. En anledning till det är att våra vänner (både offline och online) ofta kommer från arbetsplatsen där det redan finns en bredd av politiska åsikter.
Dessutom blir våra personliga nätverk mer diversifierade ju mer vi använder sociala medier. Så det borde innebära att vi exponeras för en större mångfald, inte mindre, ju mer vi använder sociala medier.
Det är dessutom de yngre som använder sociala medier mest, och det verkar vara äldre som i högre grad röstade på Donald Trump. Om nu filterbubblor och ekokammare vore den bidragande faktorn till detta valresultat (som när nyheter från högersidan med falsk information sprids på Facebook) skulle vi förvänta oss att sambandet vore tvärtom.
4. Intresserade rör sig över gränserna
De som är politiskt intresserade har ofta redan en stark politisk övertygelse och rör sig över blockgränsen och exponerar sig för nyheter som rör motståndarsidan, det vill säga nyheter som går emot deras övertygelser. De som inte är politiskt intresserade tar helt enkelt inte del av speciellt mycket nyheter från varken den ena eller andra sidan.
Detta leder till den paradoxala situationen att de som är mest mottagliga för att påverkas av information inte exponeras för den, och de som är minst mottagliga för att påverkas av information är de som exponeras mest för den.
5. Polariseringen startade innan sociala medier
Man skulle kunna tänka sig att människor som tar del av information som bekräftar vad de redan tror också kommer att bli mer extrema i sina politiska övertygelser ju längre de håller på. Men det verkar de dock inte bli, enligt en artikel jag presenterade på kommunikationskonferensen Ecrea i Prag häromdagen, som jag skrivit tillsammans med Adam Shehata och Jesper Strömbäck.
Politiska övertygelser är tvärtom relativt stabila över tid och benägenheten att exponera sig för nyheter från motståndarsidan är också relativt stabil – oberoende av varandra. Med andra ord verkar inte den politiska övertygelsen förstärka benägenheten att exponera sig för nyheter som bekräftar den egna eller andra sidan, eller vice versa. En av anledningarna är att upprepad exponering för samma typ av nyheter tappar i effekt.
Det gäller Sverige och svenskarna, men forskare från Tyskland jag pratat med under konferensen har också nått likartade resultat, dock inte publicerat i någon tidskrift ännu, liksom tidigare resultat från Nederländerna. Både Tyskland och Nederländerna har ungefär samma partisystem som Sverige.
De som pratar om ökad polarisering hänvisar ofta till USA och kraftigt vinklade medier på vänster- respektive högerkanten, mycket tack vare att det bara finns två partier och kandidater att välja mellan. Men även där tycks tendensen vara densamma.
Polariseringen inom den amerikanska kongressen och allmänheten ökade exempelvis långt innan sociala medier eller vinklade nyhetsmedier på nätet slog igenom på bred front. Vad som därför är en rimligare tolkning är att vinklade medier har vuxit fram ur en redan befintlig politisk polarisering, snarare än att vinklade medier har skapat politisk polarisering.
Om man förväxlar detta orsakssamband är det lätt att gå vilse och peka ut fel förövare, såsom filterbubblor och ekokammare, och ödsla tid på att försöka lindra problemets symptom snarare än att försöka komma till rätta med problemets orsaker.
6. Nyhetsdelningar är inte mått på hur många som tror på nyheten
Det kanske är uppenbart, men av mina diskussioner med journalister att döma behövs det påpekas upprepade gånger: bara för att en nyhet har delats tusen gånger betyder det inte att tusen personer tror att nyheten är sann.
Man kan dela en nyhet av flera skäl, till exempel för att kommentera sanningshalten i texten eller helt enkelt för att man roas av den. Inte minst delar personer på högerkanten artiklar från vänsterkanten (och vice versa) genom att påpeka det absurda i någon detalj.
Så när en nyhet har delats tusentals gånger vet vi inte varför. Vi vet bara att den delats tusentals gånger.
Sedan har vi begreppen engagemang eller interaktioner. Det är begrepp som massmedierna själva har hittat på genom att slå ihop alla siffror som rapporteras från Facebook. Facebook rapporterar nämligen antalet gillningar, kommentarer och delningar, vilket tillsammans blir ”engagemang”. En fejknyhet om valet har exempelvis fått 700 000 engagemang. Men hur ofta har den gillats, kommenterats och delats? Det vet vi inte eftersom pratet om ”engagemang” döljer den informationen. Så vi har alltså en situation där mängder av siffror slås ihop och bildar nya, större siffror. Dessa stora siffror tas sedan som ett mått på problemen i samhället: Tänk att en fejknyhet har fått 700 000 engagemang! Men eftersom vi inte vet vad som döljer sig bakom denna siffra bör man förhålla sig skeptisk och ta reda på vad som har hänt, och mer viktigt varför det har hänt. Men på inga sätt kan man utifrån blott denna information dra slutsatsen om hur det påverkar människor, som att de tror på nyheten ifråga.
Att sätta ett likhetstecken mellan antal engagemang och storleken på samhällets problem är endast ett antagande, inte ett observerbart faktum. Sluta sätta så stor tilltro till stora siffror.
Slutsats
Filterbubblor, ekokammare, selektiv exponering och confirmation bias i alla ära, det är mitt forskningsområde och jag skulle gärna vilja överdriva dess betydelse för att göra min egen forskning mer relevant. Men faktum kvarstår att det i nuläget inte kan förklara speciellt mycket av den polarisering vi ser, varken i amerikanska val (som en majoritet av forskningen utgår ifrån) eller svenska val.
Det är så många faktorer som samverkar på samma gång att det är för svårt att peka ut en enda faktor, även om det känns intuitivt när man tittar på sociala medier och ser en person som delar en artikel fylld till bredden av faktafel, och att det därmed ”måste” vara en konsekvens av användningen av sociala medier.
Men däremot kan ekokammare och filterbubblor ha stor förstärkande effekt på redan befintlig polarisering. Så när vi ser extrema avarter i sociala medier så ser vi sällan genomsnittssvensken som hamnat i en ond spiral av filterbubbla, utan oftare ser vi just den extrema avarten som har fått ett medium för att göra sin röst hörd.
Forskares uppgift är då delvis att ignorera avarterna och i stället studera majoriteten, precis som vi inte studerar en sekt för att sedan dra slutsatser om befolkningen eller religioner i allmänhet.
Men låt oss leka med tanken att filterbubblor och ekokammare är de viktigaste förklaringarna till att människor röstar som de gör. Då följer genast ett par frågor: Vad förklarar tidigare val där sociala medier inte fanns? Och varför är en republikan, i stället för en demokrat, invald som president i detta val om människor helt enkelt bara bekräftar sina egna övertygelser – borde vi inte se samma resultat vid varje val och opinionsundersökning?
När massmedierna försöker lägga större delen av fokus på just fejknyheter på Facebook som en förklaring till ett valresultatet finns det alltså all anledning att vara kritisk.
Läs mer
Se mer
På Internetdagarna 2017 höll jag en föreläsning om filterbubblor – se på YouTube.
Lyssna mer
Ställen där jag pratat mer om så kallade filterbubblor.
Sveriges Radio P1 Medierna i direktsändning: Mediers reklamjulklapp och falska filterförklaringar:
Varför spelar journalister med i hysterin om Årets julklapp? Lösenordläcka i fokus efter SVT:s granskning. Och filterbubblor och falska nyheter – fenomenen som seglat upp som roten till allt ont.
Podcasten Digitalsamtal avsnitt #059 – Den porösa filterbubblan:
”Filterbubblan” är ett dåligt definierat begrepp, och vars effekter dessutom överskattas kraftigt. Bubblorna är i själva verket väldigt porösa. Det säger Peter Dahlgren, doktorand i mediepåverkan på JMG i Göteborg.
I veckans avsnitt av Digitalsamtal pratar han bland annat om selektiv exponering och vad forskningen egentligen säger om hur mediakonsumenter väljer att gallra i informationsfloden och vilka effekter det får. Läs gärna också hans blogginlägg som kommenterar bubbeldebatten efter det amerikanska presidentvalet.
Podcasten Aning avsnitt 15. Filterbubblor med Peter Dahlgren:
Ett avsnitt i gränslandet mellan mediepåverkan, politisk kommunikation och social kognition. Hur påverkar långvarig användning av sociala medier människors världsbild? Vad är filterbubblor, selektiv exponering, ekokammare och confirmation bias? Hur bör man värdera nyheter? Medieforskaren Peter Dahlgren svarar.