
Stiftelsen för internetinfrastruktur har släppt en ny rapport vid namn Algoritmer: Så påverkar de din vardag, skriven av Jutta Haider och Olof Sundin.
Här tänkte jag redogöra för min kritik mot dels rapporten och dels ordet ”algoritmer” i största allmänhet. För det som många menar när de säger ”algoritmer” verkar egentligen vara ”mjukvara”.
Algoritm: ett nytt ord för att ersätta mjukvara
Vad är det som gör att du ser det du ser på nätet? Det är algoritmerna. Hur kan du läsa den här texten just nu? Tack vare algoritmerna. Och vad är det som gör att du kan posta en kommentar i kommentarsfältet? Du gissade rätt, det är också algoritmerna. ”Algoritm” tycks vara de senaste årens buzzword i svensk press (se diagrammet nedan) som kan förklara vad som händer i det digitala samhället.
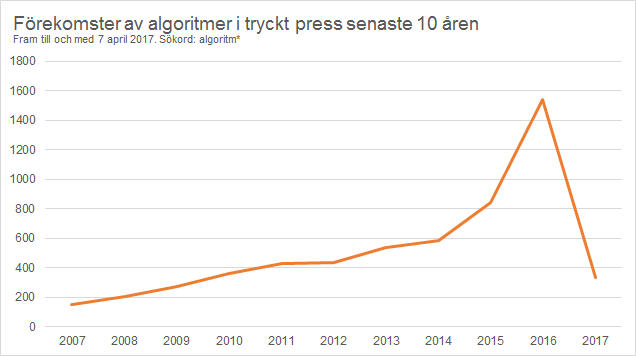
Men när ett begrepp tenderar att förklara allt blir vi inte mycket klokare av att använda det. Aristoteles påpekade redan i Retoriken (s. 152 i svenska upplagan) att en sak vi alla människor vet är vi i regel väldigt okunniga om när det omformuleras med andra ord. Detsamma kan sägas om algoritmer när det verkar få ersätta ”mjukvara” i allt högre utsträckning. Algoritmer har dokumenterats 1 600 år före Kristus, så fenomenet kan åtminstone inte påstås vara speciellt nytt (om vi nu inte förväntas jämföra med big bang), även om det har ökat i popularitet på senare år.
Google har exempelvis över 40 000 egna patent, de flesta mjukvarupatent, och det bidrar därför sällan till förståelsen när någon väljer att prata om ”Googles algoritm” – i singular dessutom. Algoritm likställs ofta med ett recept, och vi säger ju sällan att vi har lagat ”receptet” till lunch om vi inte först specificerar exakt vilket av alla tusentals recept vi talar om.
Mitt förslag är att inte göra sig själv okunnig genom att byta ut ord vi redan kan och använder till förmån för ord som är både malplacerade och på fel abstraktionsnivå. Det går utmärkt att säga ”Googles sökmotor” i stället för ”Googles algoritm”. Forskare kan fortsätta säga att de använt OLS regression för att analysera datan i stället för att säga att de använt en algoritm. Det senare kan syfta på precis vad som helst, medan det förra är någorlunda väl avgränsat. (Googles sökmotor har för övrigt mängder av algoritmer, de flesta banala, som hur länkarna till andra sidor i sökresultatet ska visas.)
Vill man prata om innehåll som skräddarsys efter individens tidigare beteenden (sökningar eller klick på länkar) är ett lämpligare ord personalisering. Då kan vi skilja mellan vad en individ själv väljer att utesluta från sin informationsmiljö (aktiv personalisering) och vad företag som Google och Facebook exempelvis bestämmer vad du ska se utifrån dina tidigare beteenden (passiv personalisering). Redan här har vi kommit till kärnfrågan (åtminstone en av dem) i stället för att trassla in oss i tekniska detaljer.
Nu vänder jag i stället blicken mot rapporten ifråga.
Kulturella värderingar kodifierade i algoritmer
Rapportförfattarna skriver (s. 9-10) att samhälleliga och kulturella normer, fördomar och liknande är inskrivna i algoritmer. Som stöd för detta argument visar de några tydliga exempel på hur detta kan ske i praktiken:
Algoritmer är kulturellt kodade
Algoritmer är en djupt integrerad del av vårt samhälle. Algoritmer ger också uttryck för dominerande föreställningar och värderingar i vår kultur. Det går att uttrycka i termer av att algoritmer kodifierar dessa föreställningar och värderingar. Vi ser det till exempel i hur en kulturs värderingar om offentlig amning och den kvinnliga kroppen leder till att Facebook censurerar alltför ”explicita” bilder på amning. Det får i sin tur genomslag världen över genom de värderingar som finns inbyggda i Facebooks algoritm, vilken automatiskt letar upp och döljer kvinnlig nakenhet. Det här leder till att även schematiskt ritade bilder på bröst vid till exempel en kampanj för bröstcancer kan bli osynliggjorda.
Det som kan framstå som självklart i den kultur där algoritmen är skapad, kan framstå som underligt, kanske till och med stötande, i en annan kultur. Andra exempel visar på rasistiska värderingar som syns i Googles och Flickrs algoritmer för automatisk taggning av bilder. Google har exempelvis behövt be om ursäkt för att en algoritm för bildbeskrivning taggade två svarta personer med ”gorillas”.
Detta är allvarligt om så vore fallet. Tittar man på referensen till tidningsartikeln säger Google att de också har råkat klassificera människor som hundar. Med rapportförfattarnas fokus på hur kulturella normer påverkar algoritmen borde slutsatsen också vara (a fortiori) att Googles värderingar är att människor är hundar och att dessa värderingar är kodifierade i algoritmen.
Dessbättre är det felaktigt, och det beror på hur klassificering av bilder går till, vilket bygger på perceptuell inlärning och är inte inskrivet i algoritmen över huvud taget.
Det handlar om att man använder en bildklassificerare och låter denna ”lära” från en mängd olika exempelbilder. Ut kommer då en modell från algoritmen som har till uppgift att klassificera nya bilder, som modellen tidigare inte har sett. Därefter släpper man lös klassificeraren (modellen) i det vilda och låter den klassificera bilder på egen hand utifrån mönster den själv hittar. Detta senare steg i mönsterigenkänningen har alltså inte programmerats av någon människa över huvud taget. Annorlunda uttryckt skapar dessa algoritmer saker utöver vad de har programmerats att göra, alltså modellen.
Däremot kan dessa producera andra typer av fel, till exempel när man stoppar in ett skevt urval av bilder i modellen. Detta beskrivs betydligt mer nyanserat i artikeln Artificial Intelligence’s White Guy Problem där forskaren Kate Crawford från Microsoft beskriver problematiken:
This is fundamentally a data problem. Algorithms learn by being fed certain images, often chosen by engineers, and the system builds a model of the world based on those images. If a system is trained on photos of people who are overwhelmingly white, it will have a harder time recognizing nonwhite faces.
Ett annat extremt exempel värt att nämna är Tay. Microsoft utvecklade en chatbot vid namn Tay på Twitter som efter ett par timmar blev nynazist på grund av att ha blivit medvetet matad med nazistiska, sexistiska och rasistiska kommentarer av andra Twitteranvändare. Detta reflekterar inte nödvändigtvis att nazistiska normer hos Microsoft har kodifierats i algoritmen, utan snarare att Tay är ett exempel på artificiell intelligens avsedd att lära sig härma andra människor. Resultatet är en extrem form av behaviorism och social inlärning, en svamp som suger åt sig allt den blir tillsagd och sedan gör likadant.
Vidare i rapporten om algoritmer står det:
Man har också funnit att Google Sök i högre utsträckning visar annonser för välavlönade jobb för manliga profiler än för kvinnliga. Dessa exempel gör det tydligt hur kulturella värderingar, fördomar och etiska förhållningssätt finns inskrivna i algoritmer som i sin tur har möjlighet att påverka andra. Algoritmer och samhälle formar därmed varandra.
Låt oss titta i referensen de hänvisar till. Där står det: ”We cannot determine who caused these findings due to our limited visibility into the ad ecosystem, which includes Google, advertisers, websites, and users.”
Det är med andra ord inte säkert att det är Googles algoritm över huvud taget som är ansvarig för resultatet, utan det kan också vara annonsörerna, webbplatserna eller användarna. Ändå skriver rapportförfattarna att det är inskrivet i algoritmer och att dessa exempel är tydliga. Så referensen de hänvisar till är med andra ord inget stöd till det argument som läggs fram i rapporten om att algoritmer är kulturellt kodade.
Algoritmer, eller rättare sagt modellerna, av ovan nämnda slag gör alltid fel i viss utsträckning, och syftet är oftast att minimera felen snarare än att göra träningen perfekt (så kallad overfitting fungerar sällan utanför det omedelbara sammanhanget).
Kan algoritmer aldrig vara kulturellt kodifierade? Jodå. Men det finns ingen logiskt tvingande nödvändighet i att en algoritm är kulturellt kodifierad. Försök exempelvis hitta den kulturella kodifieringen i kvadratroten. Föreställningen om att eventuella normer är ”inskrivna” i algoritmerna verkar snarare vara något rapportförfattarna har tillskrivit algoritmerna utifrån sina egna kulturella perspektiv.
Hade rapportförfattarna fortsatt på sin analogi som presenterades inledningsvis, att algoritmer är som recept, så hade de också kunna dra den deduktiva slutsatsen att resultatet av algoritmen till stor del också beror på vad man stoppar in i modellen. Ett bakverk är ju som bekant beroende dels av råvarorna och dels av tillagningsproceduren. Enkelt uttryckt gäller principen ”skit in, skit ut” oavsett hur bra tillagningsproceduren i övrigt är, vilket sätter fokus på hur algoritmerna har tränats snarare än hur algoritmerna är skrivna. För skillnaden mellan ett recept och en algoritm är att recept specificerar vilka råvaror du ska tillaga. Algoritmer gör det inte, utan antas kunna lösa generella problem.
Denna distinktion, som rapportförfattarna introducerar men överger, gör mig bekymrad att rapportförfattarna inte riktigt förstår algoritmer eller hur de fungerar, vilket är anmärkningsvärt med tanke på att författarna har till uppgift att lära andra hur algoritmer fungerar och dessutom har skrivit tre rapporter om ämnet för Statens medieråd, Regeringskansliet och Skolverket.
Google kan rimligen anklagas för att skriva en dålig algoritm som exempelvis prioriterar fel innehåll i deras sökmotor, liksom att de kan kritiseras för att träna algoritmen med ett skevt urval av exempel. Detta ska lyftas upp och kritiseras. Men när användare manipulerar innehållet, som modellen ifråga sedan utgår ifrån, kan Google möjligen anklagas för moralisk passivitet om detta innehåll får konsekvenser som Google inte rättar till. Likaså bör vi kritisera Google när de använder träningsdata som är skev i någon bemärkelse. (Givetvis gäller samma argument för andra företag, men Google får tjäna som exempel här.)
Det rapportförfattarna lyfter fram, de etiska aspekterna såsom transparens inför automatiskt beslutsfattande som bygger på proprietära algoritmer, är därför en mycket viktig fråga. I synnerhet om de i vid utsträckning införs allt mer i den offentliga sfären bland myndigheter.
Vidare skriver rapportförfattarna (s. 15):
Big data hanterar, som namnet antyder, stora mängder data, men syftar i sin betydelse snarare på hur man sammanför olika data för att kunna urskilja mönster. Man använder då algoritmer för att utföra så kallade förutsägande (predikativa) analyser genom att förstå hur olika skeenden hänger ihop. Det handlar inte minst om att förutspå konsumentbeteenden och individers preferenser, men andra användningsområden är också tänkbara. Exempelvis kan de ord vi söker på i Google Sök användas för att bedöma allmänhetens intresse för olika politiska frågor, för att förutse valresultat eller hur en influensaepidemi sprider sig. (Google Flu Trends, GFT)
Det kanske inte är ett lyckat exempel då Google Flu Trends är nedlagd sedan flera år tillbaka eftersom det inte fungerade.
Läs mer
Jag har nyligen skrivit ett avsnitt i en kommande rapport om metoder för insamling och analys av data via sociala medier för MSB, och då lade jag fokus (förvisso ytligt) på en del algoritmer för maskininlärning. Jag vet inte när rapporten publiceras, men kan länka in den här senare.
Filosofen John Danaher har skrivit en rad artiklar och intressanta blogginlägg om hoten från ett algokratiskt samhälle, det vill säga ett samhälle där algoritmer snarare än människor står för politiska beslut:
- The Threat of Algocracy: Reality, Resistance and Accommodation
- Algocracy as Hypernudging: A New Way to Understand the Threat of Algocracy
Se också min egen artikel, mer om algoritmer i relation till big data: