I massmedierna har en nyligen publicerad studie framställts som att känslor sprids på Facebook. Om en vän slutar skriva en massa positiva ord så skriver du fler negativa ord. Men är det verkligen så?
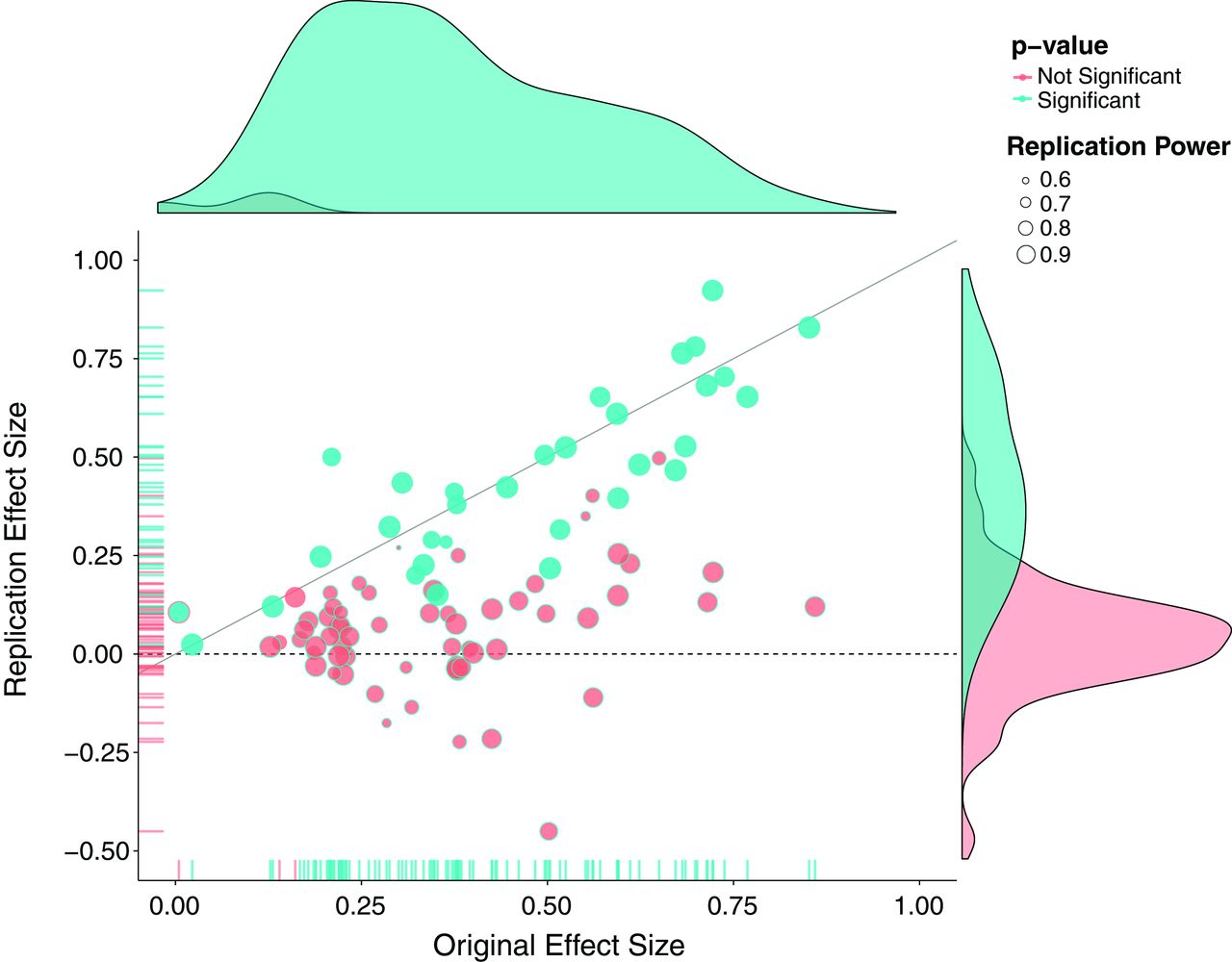
Studien tittade på hur känslor kan spridas från en människa till en annan när de pratar eller interagerar med varandra på något sätt (emotional contagion). Forskarna manipulerade nyhetsflödet hos 689 003 Facebookanvändare och visade mindre positiva och negativa inlägg för användarna för att se om de påverkades under veckan. Rent konkret så var det en algoritm som sökte igenom Facebookinlägg och dolde inlägg om de hade positiva (eller negativa) ord.
När positiva inlägg försvann så ökade antalet negativa inlägg med 0,04 procent. Och när negativa inlägg försvann så ökade antalet positiva inlägg med 0,07 procent.
Men som vanligt när massmedierna refererar till forskning (och i synnerhet effekter) så görs alla nyanser om till ett svartvitt beslut: ”Sprids känslor vidare på Facebook eller inte?” Det är dock svårt att göra om en skala till en fråga som bara har två svarsalternativ. Det korta svaret är att det finns en effekt. Men den är inte speciellt stor, och den är heller inte speciellt relevant.
1. Väldigt, väldigt liten effekt
Så här säger Facebookstudien med all sin detaljrikedom:
When positive posts were reduced in the News Feed, the percentage of positive words in people’s status updates decreased by B = −0.1% compared with control [t(310,044) = −5.63, P < 0.001, Cohen’s d = 0.02], whereas the percentage of words that were negative increased by B = 0.04% (t = 2.71, P = 0.007, d = 0.001). Conversely, when negative posts were reduced, the percent of words that were negative decreased by B = −0.07% [t(310,541) = −5.51, P < 0.001, d = 0.02] and the percentage of words that were positive, conversely, increased by B = 0.06% (t = 2.19, P < 0.003, d = 0.008). The results show emotional contagion. [mina fetmarkeringar]
Skippa de krångliga siffrorna och titta på det mest uppenbara – procentstorleken. Skriver du mindre positiva ord på Facebook så minskar antalet positiva ord som dina vänner skriver med upp till 0,1 procent. Är det mycket? Nej, inte speciellt. Det är jävligt lite i sammanhanget om vi antar att du har 150 vänner (vilket är ungefär vad en genomsnittlig användare har).
Dessutom går det att notera att effektstorleken är väldigt, väldigt liten. Cohens d är som högst 0,02 i studien. Det är motsvarigheten till att hälla en burk rödfärg i Vättern och säga att man har färgat vattnet rött. Det är visserligen sant, men hur mycket av hela sjön har egentligen färgats rött? Det är knappt synbart och förmodligen inte något man behöver ringa Länsstyrelsen för att berätta.
Såvida du inte har 100 000 vänner lär du förmodligen inte påverka dina vänner speciellt mycket med dina statusuppdateringar. Men om du nu råkar vara Robyn eller någon annan kändis så kan du förmodligen påverka dina vänner så att några av dem uttrycker sig mer positivt eller negativt.
2. Ord är inte känslor
Ett annat problem är kopplingen mellan ord och känslor. För det första har de inte mätt känslor, utan känslouttryck, och det är något helt annat. Jag kan exempelvis uttrycka mig ledsamt samtidigt som jag är väldigt glad och vice versa.
Men detta är inte ett speciellt allvarligt problem eftersom vi ändå inte kan veta vad personen på andra sidan skärmen faktiskt tycker eller känner.
Citat kan innehålla negativa ord samtidigt som Facebookinlägget i övrigt är positivt, men det spelar inte heller så stor roll. Frågan är om orden smittar eller ej.
Dessutom sprids mycket tårdrypande historier liksom solskenshistorier via videoklipp och foton, som har högre potential att uttrycka känslostämningar, så vi kan anta att effekten är betydligt större när det kommer till multimedia. Det är dock oerhört svårt att undersöka foton och videon på en så stor vetenskaplig skala eftersom det sällan går att mäta på något vettigt sätt (vilket är en allvarlig brist i största allmänhet).
Läs också Word of Psychology som skrivit en bra kritik av metoderna. Där påpekas bland annat att textanalysen är kass eftersom den inte passar för korta texter.
3. Nej, konsekvenserna är små
Forskarna säger att detta experiment visserligen har små effekter men ändå har potentialen att påverka hundratusentals människor eftersom Facebook har över en miljard användare:
More importantly, given the massive scale of social networks such as Facebook, even small effects can have large aggregated consequences (14, 15): For example, the well-documented connection between emotions and physical well-being suggests the importance of these findings for public health. Online messages influence our experience of emotions, which may affect a variety of offline behaviors. And after all, an effect size of d = 0.001 at Facebook’s scale is not negligible: In early 2013, this would have corresponded to hundreds of thousands of emotion expressions in status updates per day.
Men detta är inte helt sant.
Människor är grupperade i kluster och information sprids inom kluster snarare än mellan dem. Det innebär att information på Facebook skickas mellan vänner och sällan når längre än så, och det beror i huvudsak på att det är vänner och kollegor som pratar med varandra på Facebook. Det finns förstås undantag där information sprids väldigt långt, upp till 82 steg från källan har uppmätts, men de är lätträknade i jämförelse. På andra sociala medier, såsom Twitter, är det däremot mer främlingar som talar med varandra, men däremot visar forskning att även på Twitter tenderar människor att prata med likasinnade.
Jag tror snarare att de långsiktiga effekterna av att använda sociala medier är betydligt ”starkare”, vilket också är något jag ska undersöka i min egen doktorsavhandling.
Och sedan den etiska biten att manipulera Facebookflöden utan att användarna är medvetna om det. Ja, den frågan ignorerar jag helt i detta inlägg och överlåter jag till moralfilosofer i stället. Det verkar dock som att de bröt mot många etiska regler inom vetenskapen, bland annat om samtycke och att man ska informera deltagarna om vad som har hänt.
Slutsats
Kan du påverka dina vänners känslor på Facebook? Nej. Effekten i den här studien är så liten så att jag vill påstå att den är försumbar och helt enkelt kan ignoreras.
Eftersom forskarna heller inte tar hänsyn till mediets egenskaper (hur människor använder Facebook och hur information sprids på Facebook) gör det att de av misstag sätter ett likhetstecken mellan känslornas spridningsmöjlighet med antal användare. Men de flesta Facebookanvändare har inte 100 000 vänner.
Det vill säga, information sprids mest mellan vänner och det innebär att informationen inte kommer speciellt långt. Därmed blir den känslomässiga spridningen (emotional contagion) inte heller speciellt påtaglig då de psykologiska teorierna inte kan överföras direkt till ett medium utan att man också tar hänsyn till hur folk använder medierna. Det är därför man måste ha kunskap om både psykologi och medier för att kunna göra psykologiska fältexperiment med medier.
Sammanfattningsvis, även om effekten hade varit större så hade den fortfarande inte varit speciellt relevant.
Betyder detta att Facebookanvändare är immuna mot känslomässig påverkan? Inte alls. Testa själv genom att skriva en statsuppdatering om att dina föräldrar har dött. Du kommer garanterat att påverka dina vänners känsloyttringar på Facebook väldigt mycket. Men räkna inte med att det kommer att spridas speciellt långt. Och räkna inte heller med att någon kommer att ta dig på allvar i fortsättningen.
Några som skrivit om studien
Här är ett axplock av massmedier och bloggar som skrivit om Facebookstudien:
Foto: Evan Raskob